Tasks
The POTION project is structured in three main tasks:
- Task 1: Perception-based t-f representation of audio signals
- Task 2: Development and implementation of a t-f masking model
- Task 3: Optimization of perceptual audio codecs
Task 1
The main goal of this task is to investigate new linear t-f representations by exploiting the recently developed non-stationary Gabor theory as a mathematical background. These transforms should be designed so that t-f resolution mimics the t-f analysis properties of the auditory system and (i) perfect reconstruction is possible (ii) no redundancy is introduced or (iii) redundancy is exploited to maximize the coding efficiency. This task also investigates alternative methods that perform an adaptive decomposition of audio signal based on psycho-acoustic principles, but not necessary with perfect reconstruction.
Sub-task 1A: Properties of ERBLet
This transform is a special case of non-stationary Gabor transform which follows the ERB (Equivalent Rectangular Bandwidth) perceptual frequency scale, with perfect reconstruction capability. It can be seen as a non-uniform filterbank where the center frequency and the bandwidth of each filter matches the ERB scale. Using a straightforward synthesis scheme (also called painless case in the litterature), ERBLet has a redundancy factor greater than 2 (depending on the number of frequency bands), which is too much for an application to audio coding. An iterative synthesis algorithm that allows to reduce the redundancy is also proposed, but with a much higher complexity.
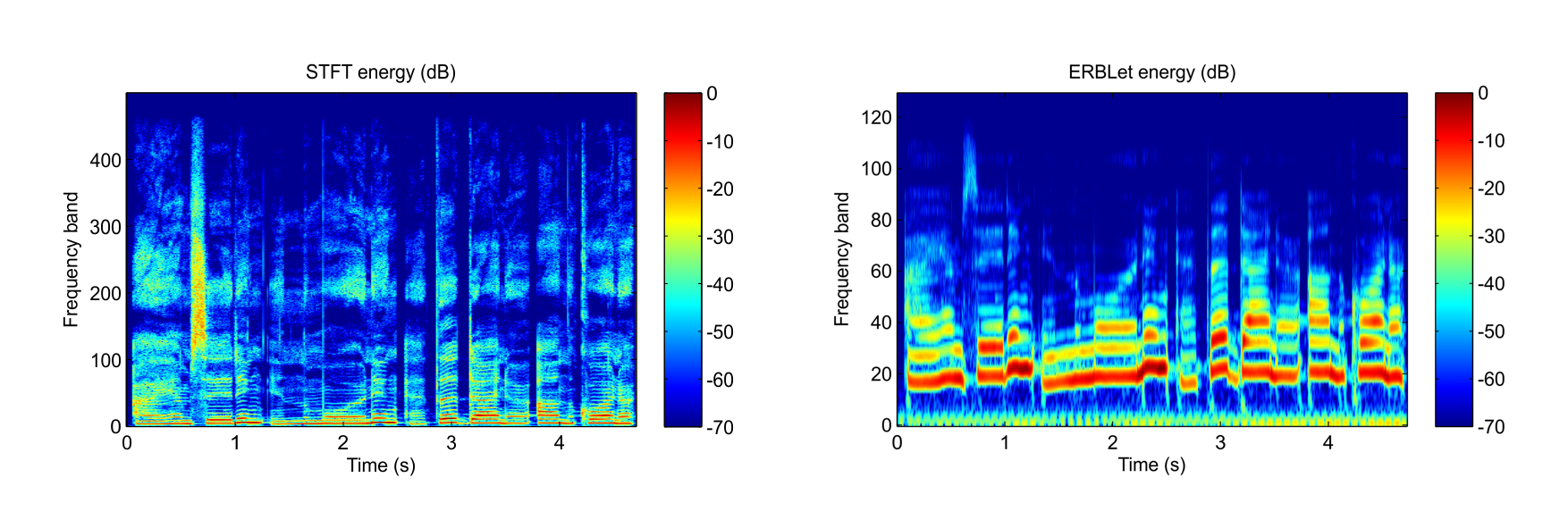
Energy in the time-frequency plane for the first measures of "Tom's Diner" by Suzanne Vega.
Short-Time Fourier Transform anaysis (500 frequency bands) and ERBLet analysis (128 bands, i.e. 3 bands per ERB)
Sub-task 1B: Implementation of ERBLet
The ERBLet was implemented using a highly efficient scheme and was included in the the Large Time-Frequency Analysis Toolbox (LTFAT) for Matlab/Octave. The latest version of LTFAT can be downloaded here.
Sub-task 1C: Non-stationary Discrete Cosine Transforms
The idea is to propose a new discrete cosine transform using the same construction method as with ERBLet. We defined the ERB-MDCT transform that also follows the ERB scale, but with a redundancy very close to 1. Thus, ERB-MDCT is more suitable for audio coding than ERBLet. However, in ERB-MDCT, only the center of frequency bands follows the ERB scale. The bandwidth is constrained by the quasi-orthogonality of the transform. This results in narrower frequency bands than with ERBLet. The overlap between bands is also reduced.
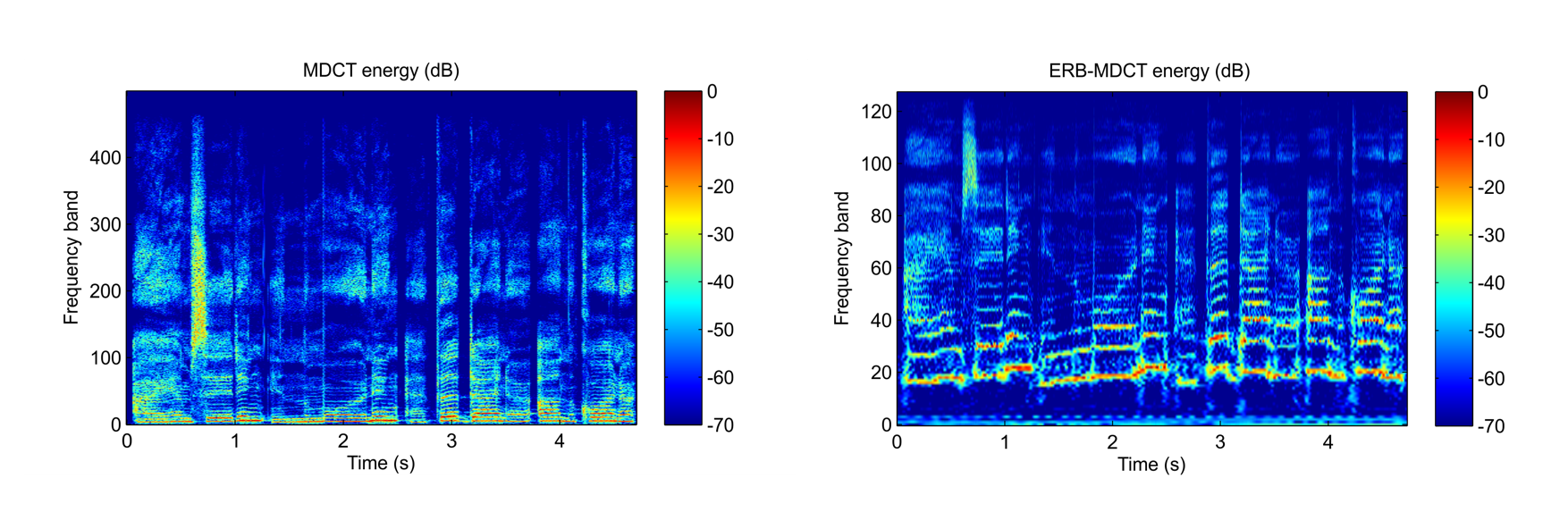
Energy in the time-frequency plane for the first measures of "Tom's Diner" by Suzanne Vega.
MDCT anaysis (500 frequency bands) and ERB-MDCT analysis (128 bands, i.e. 3 bands per ERB)
Sub-task 1D: Perceptual adaptive decompositions
For lossy audio coding applications, perfect reconstruction is not mandatory. Thus, we also consider adaptive decomposition of audio signal that optimize a perceptual criterion. This class of methods usually offers more flexibility than perfectly invertible transforms. A new version of perceptual Matching Pursuits algorithm with Gabor dictionnaries was proposed. We also considered the sparse decomposition over a union of MDCT bases, with explicit sparsity and perceptive distortion measures using a time-frequency hearing model. This method can be seen as the continuation of the study by Ravelli et. al..
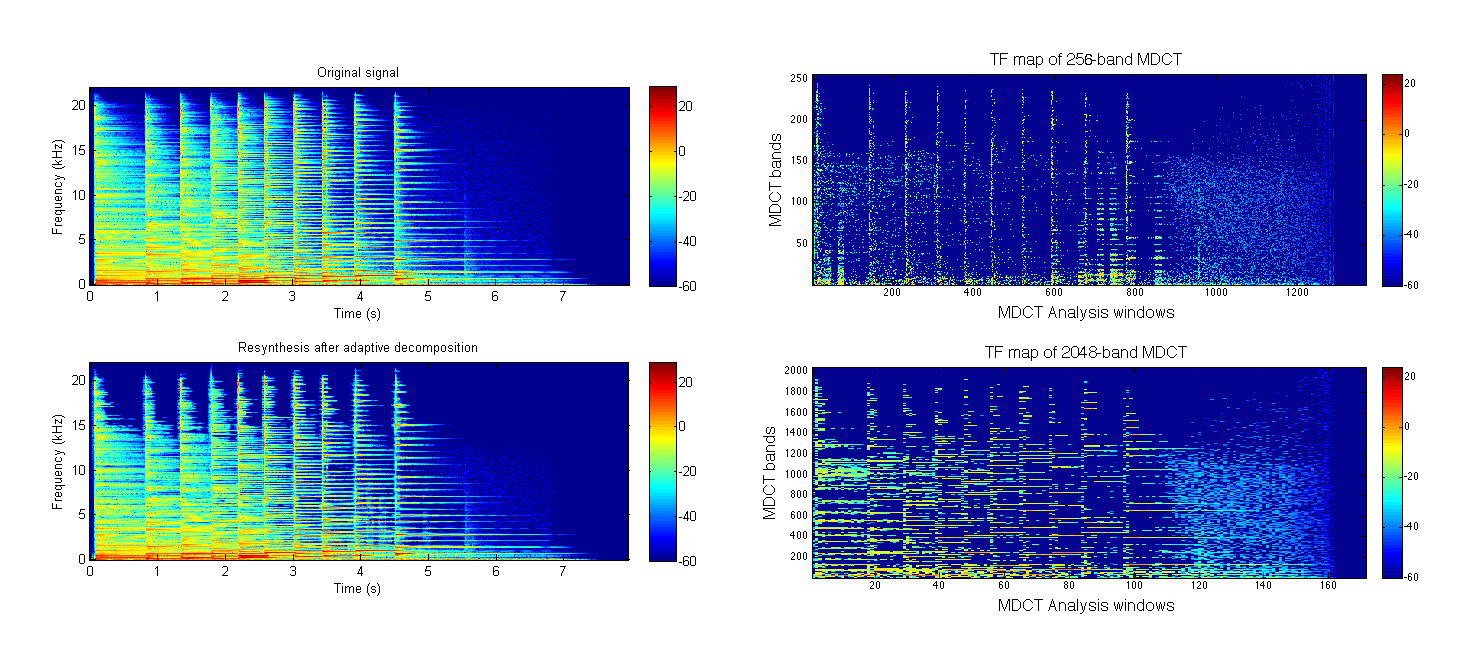
Energy (dB) in the time-frequency plane for a harpsichord signal and its decomposition on a union of 2 MDCTs using the FISTA algorithm.
On the right, energy (dB) of transform coefficients for each MDCT size is plotted in the time-frequency plane.
The target sparsity ratio w.r. to the MDCT coefficients is 15% (30% w.r. to the samples in the time domain).
Corresponding sound samples are available here.
Task 2
Based on psychoacoustical data collected by the partners in previous projects and on literature data, a new complex model of t-f masking will be developed and implemented in a perceptually-motivated transform built in task 1. Additional psychoacoustical data required for the development of the model involving frequency, level, and duration effects in (t-f) masking for either single or multiple maskers will be collected. It will be calibrated and validated by listening tests with synthetic and real-world sounds.
Sub-task 2A: Psychoacoustical experiments
Prelininary psychoacoustic experiments have been conducted at the ARI to assess the effects of masker frequency and level on the spread of time-frequency masking. Additional conditions have been added to explore the effects of target duration and binaural presentation of the masker. Preliminary data are currently under analysis before the main experiment starts.
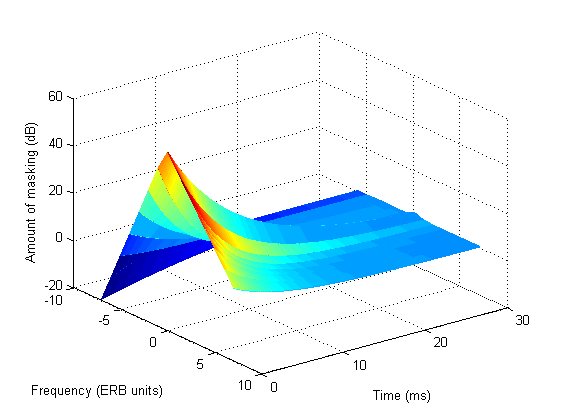
Preliminary model for the time-frequency masking kernel in ERB frequency scale.
Measures were made with Gaussian Gabor stimuli (masker and target).
Task 3
This task represent the main application of the projet. It consists in the implementation of coding techniques in order to build complete coding/decoding algorithms taking into account the results from both tasks 1 and 2. These algorithms will be optimized and compated to state-of-the art.